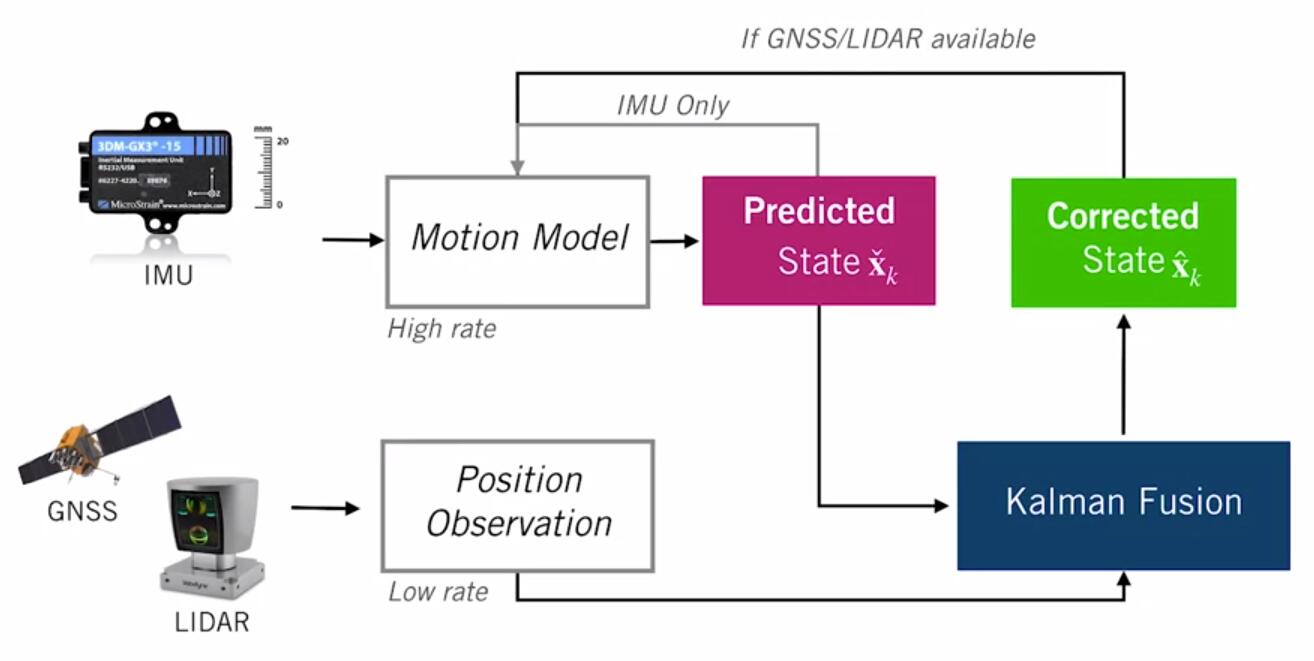
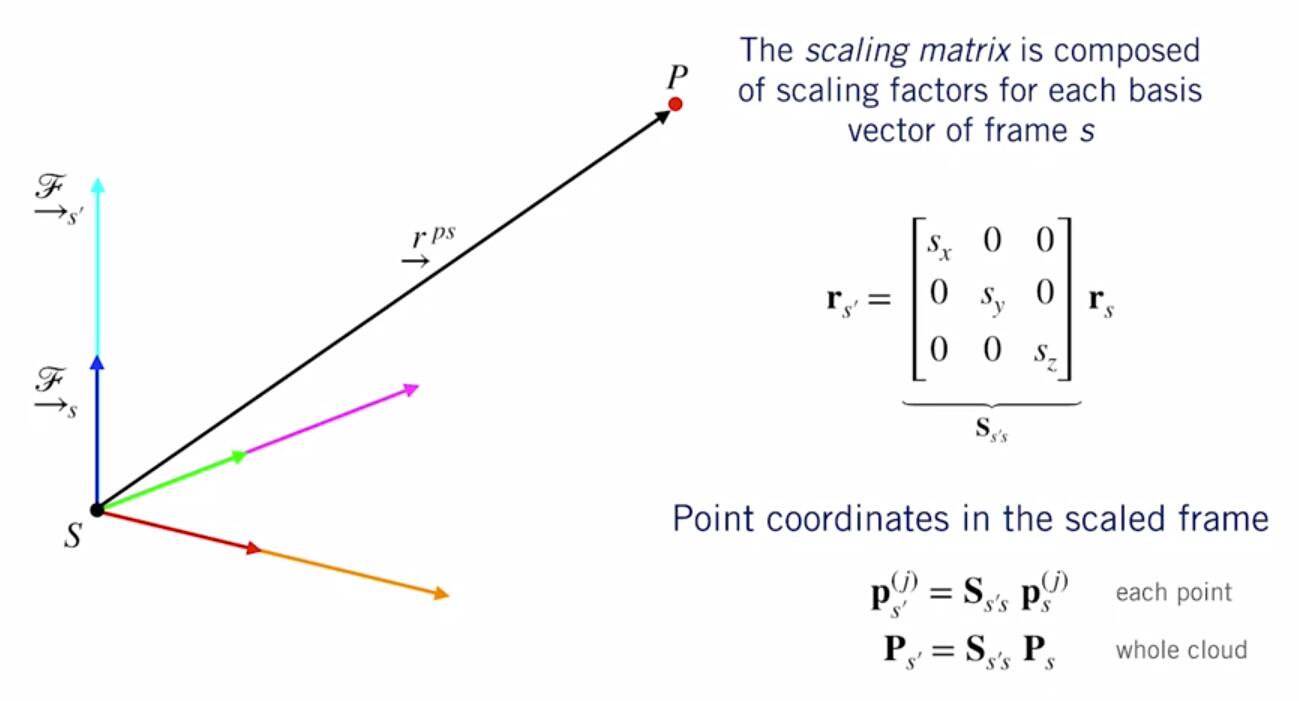
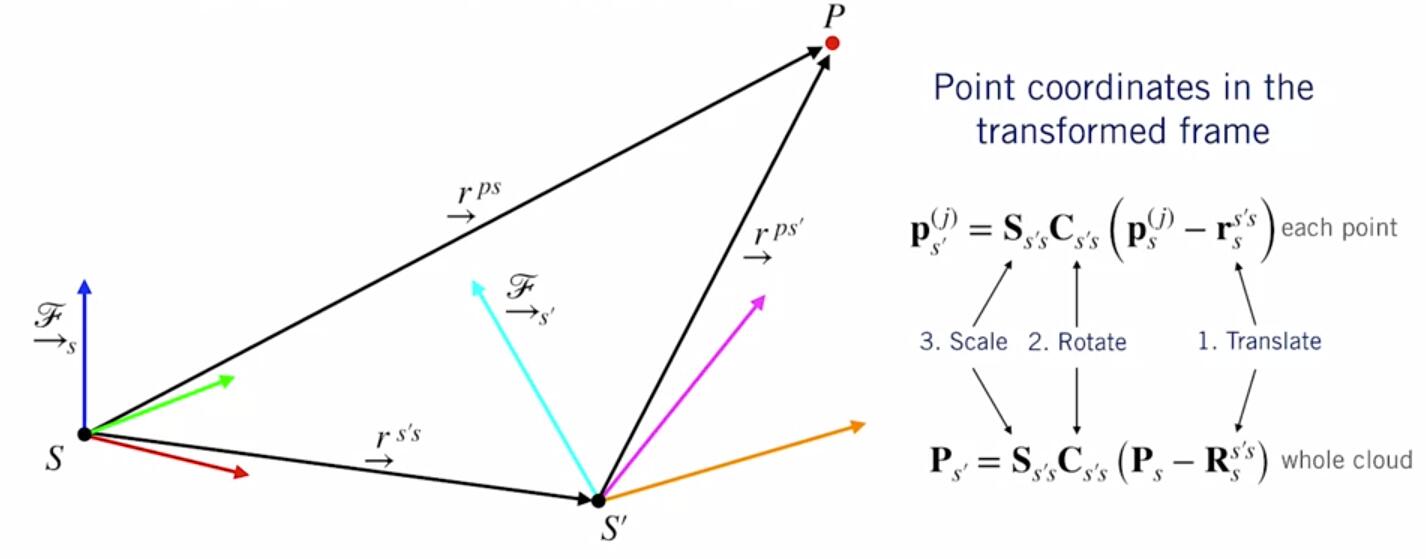
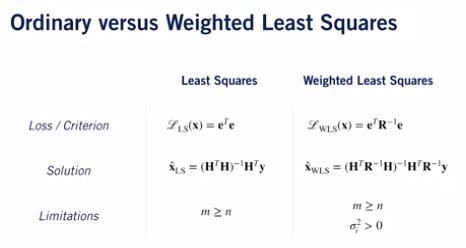
From Coursera, State Estimation and Localization for Self-Driving Cars by University of Toronto
https://www.coursera.org/learn/visual-perception-self-driving-cars
Visual Features - Detection, Description and Matching
Introduction to Image features and Feature Detectors
Introduction to feature detecors
Feature extraction
- Application: image stitching
- given two images from two different cameras, we would like to stitch them together to form a panorama.
- First, we need to identify distinctive points in our images. We call this point image features.
- Second, we associate a descriptor for each feature from its neighborhood.
- Finally, we use these descriptors to match features across two or more images.
- Features are points of interest in an image
- Points of interest should have the following characteristics:
- Saliency: distinctive, identifiable,and different from its immediate neighborhood
- Repeatability: can be found in multiple images using same operations
- Locality: occupies a relatively small subset of image space
- Quantity: enough points represented In the image
- Efficiency: reasonable computation time
- How to choose the points of interest:
- Repetitive texture less patches are challenging to detect consistently
- Patches with large contrast changes (gradients) are easier to detect(edges)
- Gradients in at least two(significantly) different orientations are the easiest to detect(corners)
- The most famous corner detector is the Harris Corner Detector, which uses image gradient information to identify pixels that have a strong change in intensity in both x and y directions.
Algorithms used
- Harris[corners]: Easy to compute, but not scale invariant.
- meaning that the corners can look different depending on the distance the camera is away from the object generating the corner.
- Harris-Laplace[corners]: Same procedure as Harris detector, addition of scale selection based on Laplacian. Scale invariance.
- Features from accelerated segment test(FAST) (corners): Machine learning approach for fast corner detection.
- high computational efficiency and solid detection performance
- Laplacian of Gaussian(LOG) detector[blobs]: Uses the concept of scale space in a large neighborhood(blob). Somewhat scale invariant.
- Difference of Gaussian(DOG) detector[blobs]: Approximates LOG but is faster to compute
Feature Descriptors
Feature descriptor definition
- Feature: Point of interest in an image defined by its image pixel coordinates [u,v]
- Descriptor f: an n dimensional vector associated with each feature.
- The descriptor has the task of providing a summary of the image information in the vicinity of the feature itself, and can take on many forms.
- Feature descriptors should have the following characteristics:
- Repeatability: manifested as robustness and invariance to translation, rotation,scale, and illumination changes
- Distinctiveness: should allow us to distinguish between two close by features,very important for matching later on
- Compactness & Efficiency: reasonable computation time
- Designing Invariant Descriptors: SIFT
- Scale Invariant Feature Transform (SIFT)descriptors
- Given a feature in the image, the shift descriptor takes a 16 by 16 window of pixels around it, we call this window the features local neighborhood.
- then separate this window in to four 4 by 4 cells such that each cell contains 16 pixels.
- Next we compute the edges and edge orientation of each pixel in each cell using the gradient filters.
- For stability of the descriptor, we suppress weak edges using a predefined threshold as they are likely to vary significantly in orientation with small amounts of noise between images.
- Finally, we compute a 32 dimensional histogram of orientations for each cell. And concatenate the histograms for all four cells to get a final 128 dimensional histogram for the feature at hand, we call this histogram or descriptor.
- Scale Invariant Feature Transform
- SIFT is an example of a very well human engineered feature descriptor, and is used in many state-of-the-art systems
- The above process is usually compute on rotatedand scaled version of the 16x16 window, allowing for better scale robustness
- Combined with the DOG feature detector, SIFT descriptors provide a scale,rotation, and illumination invariant detector/descriptor pair.
Algorithms
Other Descriptors:
- Speeded-Up Robust Features (SURF)
- Gradient Location-Orientation Histogram (GLOH)
- Binary Robust Independent Elementary Features (BRIEF)
- Oriented Fast and Rotated Brief (ORB): free to use commertially
- Many more!
Feature Matching
Match features based on a predefined distance function
- Feature Matching: Given a feature and its descriptor in image 1, find the best match in image 2
- Define a distance function $d(f_i,f_j)$ that compares the two descriptors
- For every feature $f_i$ in Image 1:
- Compute $d(f_i,f_j)$ with all features $f_j$ in image 2
- Find the closest match $f_c$, the match that has the minimum distance. This feature is known as the nearest neighbor.
- Keep this match only if $d(f_i,f_j)$ is below threshold $\delta$
- Distance Function
- Sum of Squared Differences (SSD): $d(f_i, f_j) =\sum^D_{k=1} (f_{i,k} - f_{j,k})^2$
- Sum of absolute differences (SAD): $d(f_i, f_j) = \sum^D_{k=1} |f_{i,k} - f_{j,k}|$
- Hamming Distance: $d(f_i, f_j) = \sum^D_{k=1} XOR(f_{i,k} - f_{j,k})$
- Brute force feature matching might not be fast enough for extremely large amounts of features
- Use a multidimensional search tree, usually a k-d tree to speed the search by constraining it spatially
- Both of these matchers are implemented in OpenCV as:
cv2.BFMatcher(): Brute force matcher;cv2.FlannBasedMatcher(): K-D tree based approximate nearest neighbor matcher
Feature Matching: Handling Ambiguity in Matching
- Ambiguous matches: more than one feature points can be found to have the minimum distance when do feature matching.
- The solution is to use distance ratio:
- Compute $d(f_i,f_j)$ for each feature, $f_i$, in image 1, with all features, $f_j$, in image 2
- Find the closest match $f_c$
- Find the second closest match $f_s$
- Find how better the closest match is than the second closest match. This can be done through distance ratio: $0 \leq \frac{d(f_i,f_c)}{d(f_i,f_s)} \leq 1$
- If the distance ratio is close to one, it means that according to our descriptor and distance function, fi matches both fs and fc. In this case, we don’t want to use this match in our processing later on, as it clearly is not known to our matcher which location in image two corresponds to the feature in image one.
- So the Updated Brute Force Feature Matching:
- Define a distance function $d(f_i,f_j)$ that compares the two descriptors
- Define distance ratio threshold $\rho$
- For every feature $f_i$ in Image 1:
- Compute $d(f_i,f_j)$ with all features $f_j$ in image 22.
- Find the closest match $f_c$ and the second closest match $f_s$
- Compute the distance ratio
- Keep matches with distance ratio $< \rho$
Outlier Rejection
Three-step feature extraction framework for the real-world problem of vehicle localization
- Localization problem is defined as follows:
- given any two images of the same scene from different perspectives, find the translation $T=[t_u, t_v]$, between the coordinate system of the first image , and the coordinate system of the second image.
- also need to solve for the scale and skew due to different viewpoints.
- Matched feature pairs in images 1 and 2:
- $f^{(1)}_i, f^{(2)}_i i \in [0…N]$
- $f^{(1)}_i = (u^{(1)}_i, v^{(1)}_i)$
- Model: $u^{(1)}_i + t_u = u^{(2)}_i$, $v^{(1)}_i + t_v = v^{(2)}_i$
- solve using least squares: $t_u = \frac 1N \sqrt{\sum_i (u^{(1)}_i - u^{(2)}_i)^2}$ $t_v = \frac 1N \sqrt{\sum_i (v^{(1)}_i - v^{(2)}_i)^2}$
Outliers and ANSAC algorithm
- Outliers can be handled using a model-based outlier rejection method called Random Sample Consensus (RANSAC)
RANSAC algorithm: - Initialization:
- Given a model, find the smallest number M of data points or samples needed to compute the parameters of this model. In the above case is $t_u, t_v$
- Main loop:
- Randomly select M samples from the data.
- Compute the model parameters using only the M samples selected from the data set.
- Use the computed parameters and count how many of the remaining data points agree with this computed solution. The accepted points are retained and referred to as inliers.
- if the number of inliers C is satisfactory, or if the algorithm has iterated a pre-set maximum number of iterations, terminate and return the computed solution and the inlier set.
- Else, go back to step two and repeat.
- Finally, recompute and return the model parameters from the best inlier set: The one with the largest number of features.
Visual Odometry
Visual Odometry(VO): is the process of incrementally estimating the pose of the vehicle by examining the changes that motion induces on the images of its onboard cameras
- VO Pros:
- Not affected by wheel slip in uneven terrain, rainy/snowy weather, or other adverse conditions.
- More accurate trajectory estimates compared to wheel odometry.
- VO Cons:
- Usually need an external sensor to estimate absolute scale
- Camera is a passive sensor,might not be very robust against weather conditions and illumination changes
- Any form of odometry (incremental state estimation) drifts over time
- Problem Formulation:
- Estimate the camera motion $T_k$ between consecutive images $l_{k-1}$ and $l_k$
- Concatenating these single movements allows the recovery of the full trajectory of the camera, given frames $C_1, …, C_m$
- General process of visual odometry:
- Given: two consecutive image frames $I_{k-1}$ and $I_k$
- First, perform feature detection and description. We end up with a set of features $f_{k-1}$ in image k-1 and $f_k$ in image of k.
- We then proceed to match the features between the two frames to find the ones occurring in both of our target frames.
- After that, we use the matched features to estimate the motion between the two camera frames represented by the transformation $T_k$.
- Motion estimation:
- depends on what type of feature representation we have:
- 2D-2D: both $f_{k-1}$ and $f_k$ are defined in Image coordinates
- 3D-3D: both $f_{k-1}$ and $f_k$ are specified in 3D
- 3D-2D: $f_{k-1}$ is specified in 3D and $f_k$ are their corresponding projection on 2D
- depends on what type of feature representation we have:
- Perspective N Point (PNP)
- Given feature locations in 3D, their corresponding projection in 2D, and the camera intrinsic calibration matrix k,
- Solve for initial guess of [R|t] using Direct Linear Transform(DLT): Forms a linear model and solves for [R|t], with methods such as singular value decomposition(SVD)
- Improve solution using Levenberg-Marquardt algorithm(LM)
- Need at least 3 points to solve(P3P), 4 if we don’t wantambiguous solutions.
- Finally, RANSAC can be incorporated into PnP by assuming that the transformation generated by PnP on four points is our model.
- We then choose a subset of all feature matches to evaluate this model and check the percentage of inliers that result to confirm the validity of the point matches selected.