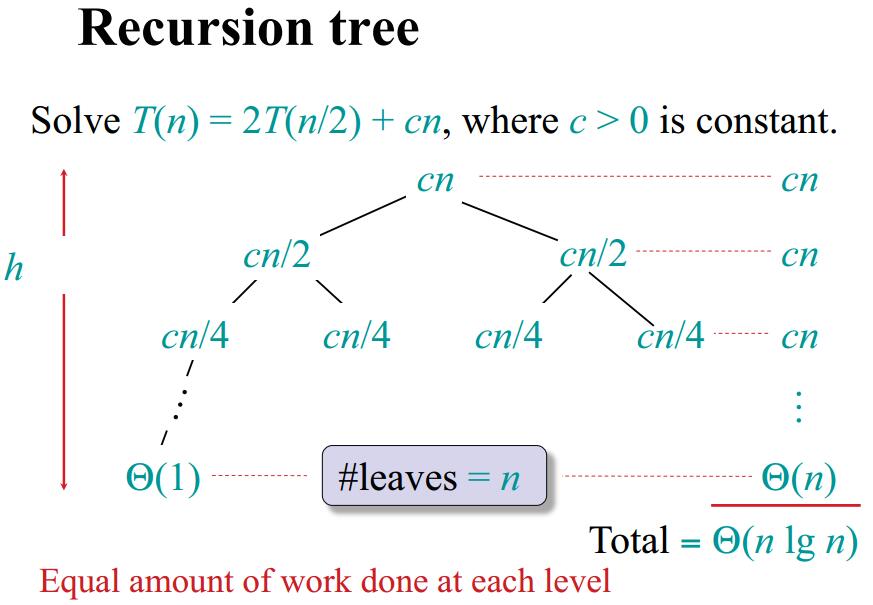
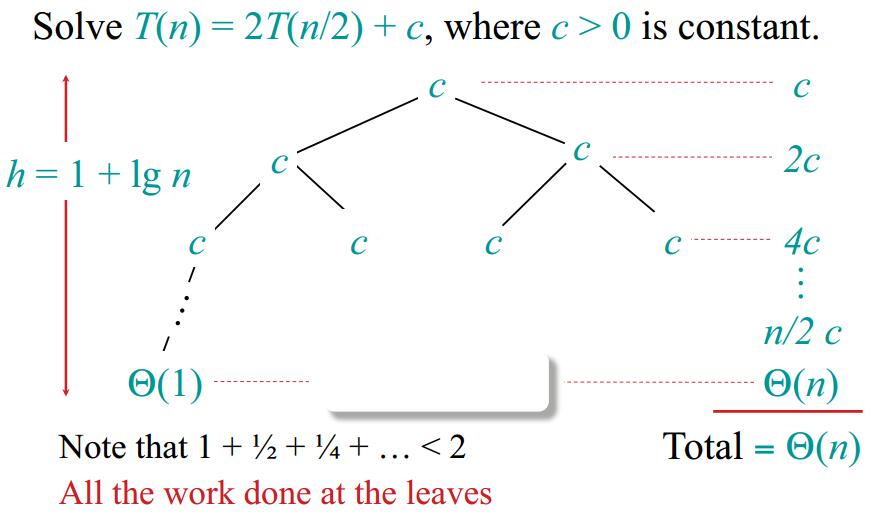
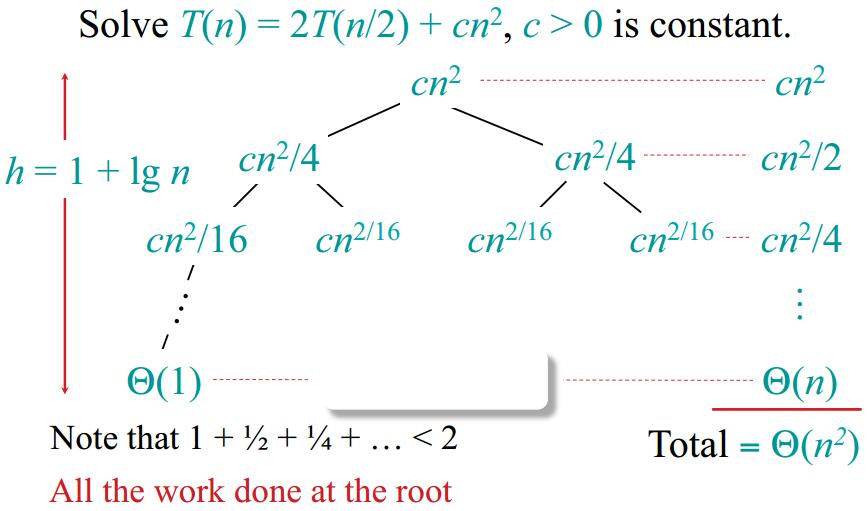
Dictionary and Motivation
Dictionary problem
- Dictionary is a abstract data tupe(ADT).
- Which means it maintains a set of items, each with a key
- The available operations are:
- insert(item): add item to the set (The key must be unique, otherwise overide an exsiting key)
- delete(item): remove item from set
- search(key): return item with key if it exists
Balanced BST solve in $O(lg n)$ time per operation. The goal is to make each operation $O(1)$ time.
(remember that BST etc. are data structure, which can be seen as the implementation of ADT)
Motivation
Dictionaries are perhaps the most popular data structure in CS
- built into most modern programming languages (Python, Perl, Ruby, JavaScript, Java, C++, C#, . . . )
- e.g. best docdist code: word counts & inner product
- implement databases: (DB HASH in Berkeley DB)
- English word → definition (literal dict.)
- English words: for spelling correction
- word → all webpages containing that word
- username → account object
- compilers & interpreters: names → variables
- network routers: IP address → wire
- network server: port number → socket/app.
- virtual memory: virtual address → physical
Prehashing and Hashing
How to solve the dictionary problem that is to make operation time to $O(1)$?
Simple Approach: Direct Access Table
This means items would need to be stored in an array, indexed by key (random access). But this has two problems:
- keys must be nonnegative integers (or using two arrays, integers)
- if the key happens to have large range, then need large space — e.g. one key is 2256, even with no other keys, the table must have take that space.
Solution
Solution to 1: “prehash” keys to integers
- In theory, possible because keys are finite ⇒ set of keys is countable
- In Python: hash(object) (actually hash is misnomer, should be “prehash”) where object can be a number, string, tuple, etc. or object implementing hash (default = id = memory address)
- In theory, x = y ⇔ hash(x) = hash(y)
- Python applies some heuristics for practicality: for example, hash(‘\0B ’) = 64 = hash(‘\0\0C’)
- Object’s key should not change while in table (else cannot find it anymore)
- No mutable objects like lists
Solution to 2: hashing
- Reduce universe U of all keys (say, integers) down to reasonable size m for table
- idea: m ≈ n = number of keys stored in dictionary
- hash function h: $U → {0, 1, . . . , m − 1}$
- two keys $k_i, k_j ∈ K$ collide if $h(k_i) = h(k_j)$
Hash Function: A function that converts a given big phone number to a small practical integer value. The mapped integer value is used as an index in hash table.
How do we deal with collisions? We will see two ways
- Chaining
- Open addressing: in Lec10
Chaining
Linked list of colliding elements in each slot of table
- Search must go through whole list T[h(key)]
- Worst case: all n keys hash to same slot ⇒ Θ(n) per operation
Simple uniform hashing
An assumption (cheating): Each key is equally likely to be hashed to any slot of table, independent of where other keys are hashed.
let n = number of keys stored in table
m = number of slots in table
load factor α = n/m = expected number of keys per slot = expected length of a chain
Performance:
This implies that expected running time for search is $Θ(1+α)$ — the 1 comes from applying the hash function and random access to the slot whereas the $α$ comes from searching the list. This is equal to $O(1)$ if $α = O(1)$, i.e., $m = Ω(n)$.
Hash Function
Following are three methods to achieve the above performance
Division Method:
$$h(k) = k \; mod \; m$$
This is practical when m is prime but not too close to power of 2 or 10 (then just depending on low bits/digits).
But it is inconvenient to find a prime number, and division is slow.
Multiplication Method:
$$h(k) = [(a · k) \; mod \; 2^w] \gg (w − r)$$
where a is random, k is w bits, and $m = 2^r$.
This is practical when a is odd & $2^{w−1}$ < $a$ < $2^w$ & a not too close to $2^{w−1}$ or $2^w$.
Multiplication and bit extraction are faster than division.
Universal Hashing:
For example: $h(k) = [(ak+b) \; mod \; p] mod \; m$ where a and b are random $∈ {0, 1, . . . p−1}$, and p is a large prime ($> |U|$).
This implies that for worst case keys $k_1 \ne k_2$, (and for a, b choice of h): $$Pr_{a,b}(event \; X_{k_1k_2}) = Pr_{a,b}\{h(k_1)=h(k_2)\} = \frac 1m$$